YOLOv5改进系列(十九) 更换Google的优化器Lion
文章目录
- 理论
- 先说结果
- 论文实验
- 超参设置
- 延伸思考
- 文章小结
- 引入谷歌Lion优化器
- 添加方式
- 实验结果
昨天在Arixv上发现了Google新发的一篇论文*《Symbolic Discovery of Optimization Algorithms》,主要是讲自动搜索优化器的,咋看上去没啥意思,因为类似的工作也有不少,大多数结果都索然无味。然而,细读之下才发现别有洞天,原来作者们通过数千TPU小时的算力搜索并结合人工干预,得到了一个速度更快、显存更省的优化器Lion(EvoLved Sign Momentum,不得不吐槽这名字起得真勉强),并在图像分类、图文匹配、扩散模型、语言模型预训练和微调等诸多任务上做了充分的实验,多数任务都显示Lion比目前主流的AdamW等优化器有着更好的效果。
更省显存还更好效果,真可谓是鱼与熊掌都兼得了,什么样的优化器能有这么强悍的性能?本文一起来欣赏一下论文的成果。

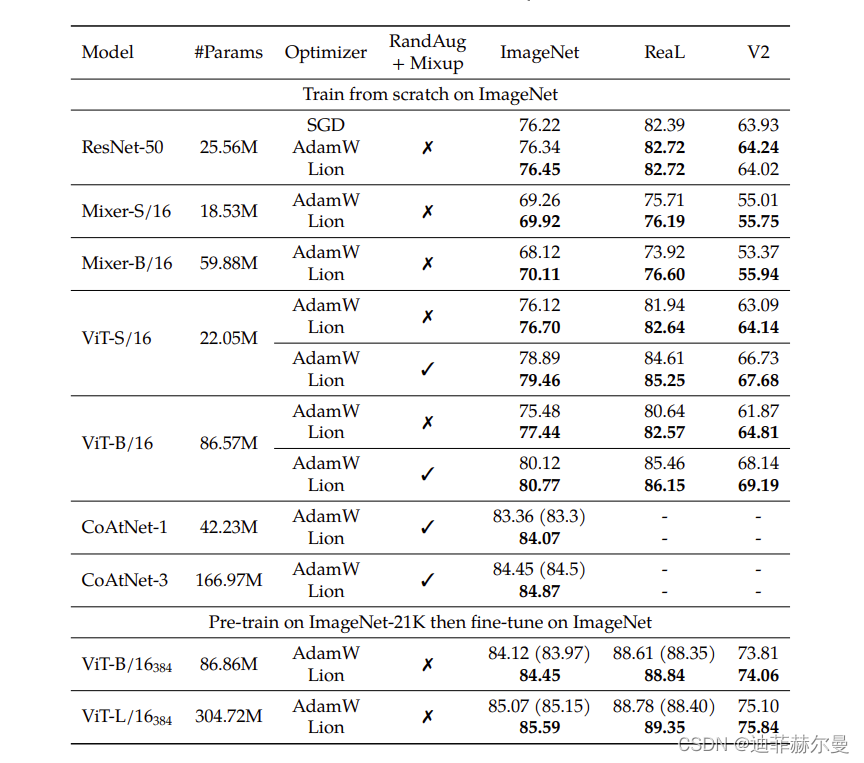
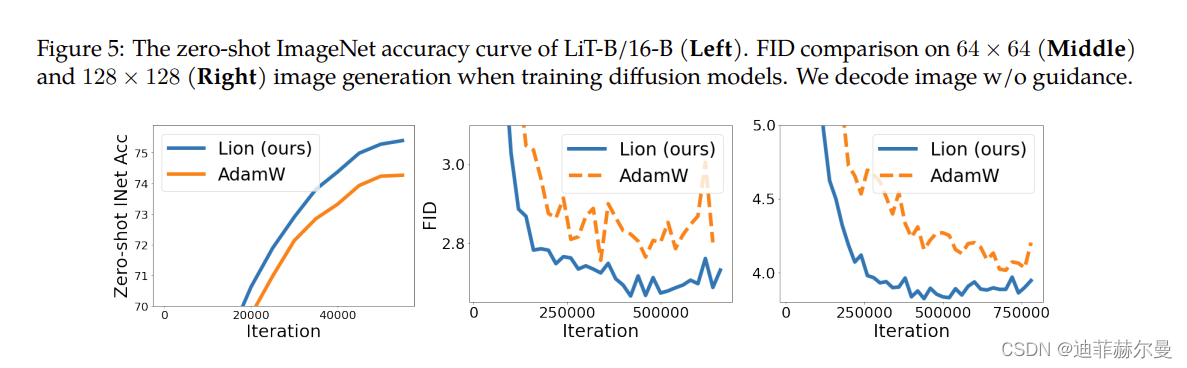
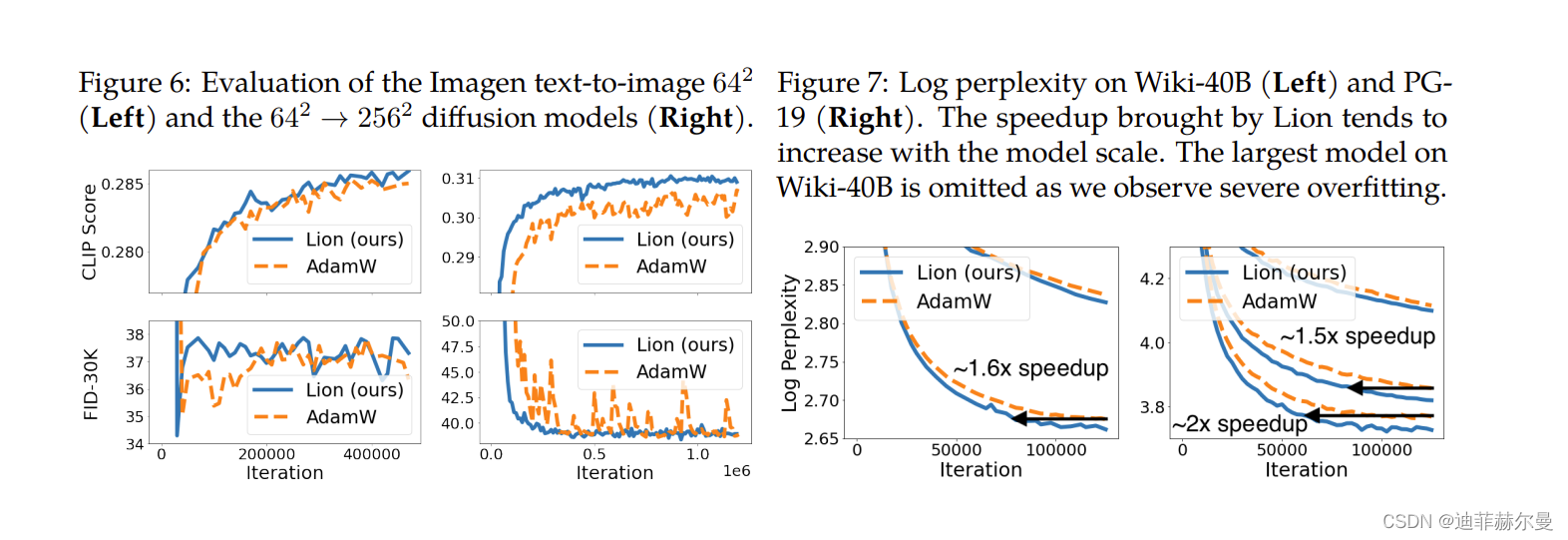
本文开头就说了,Lion在相当多的任务上都做了实验,实验结果很多,下面罗列一些笔者认为比较关键的结果。
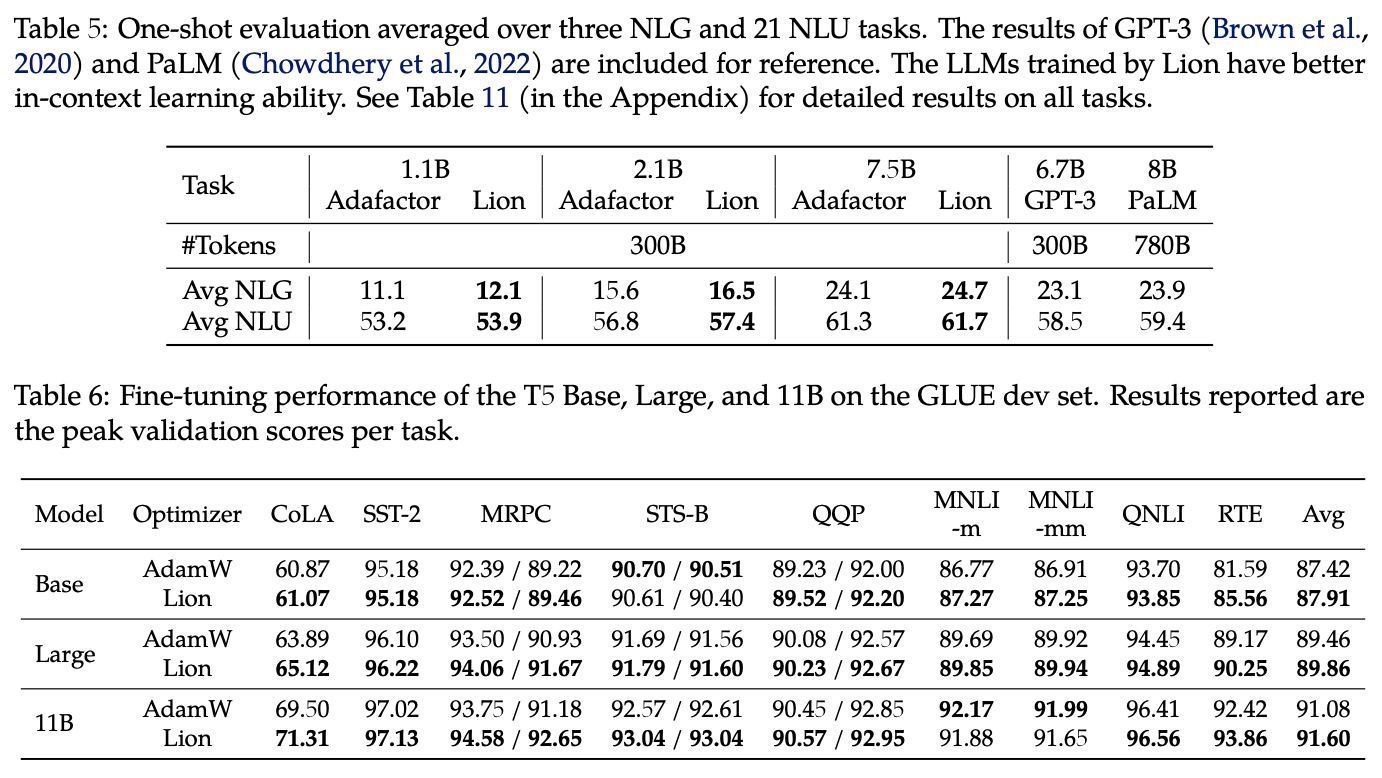
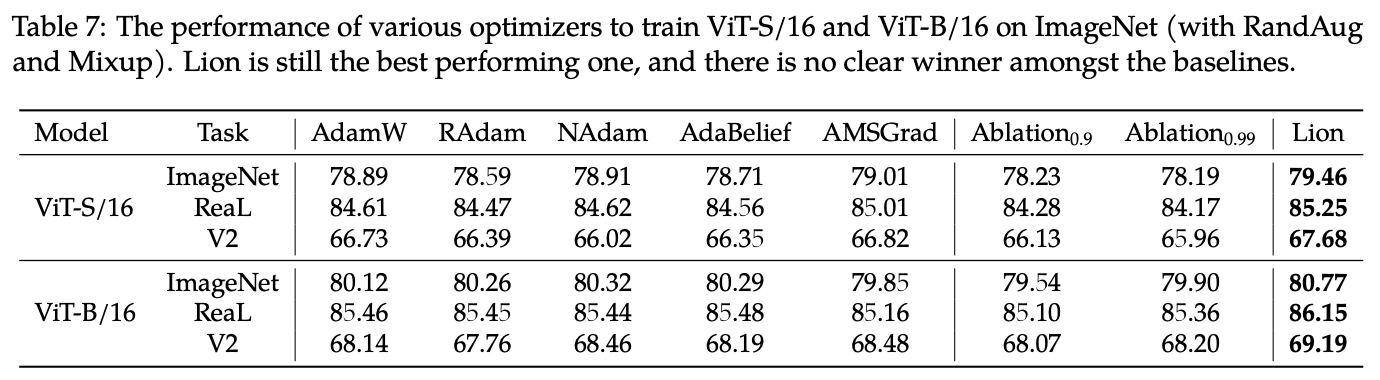


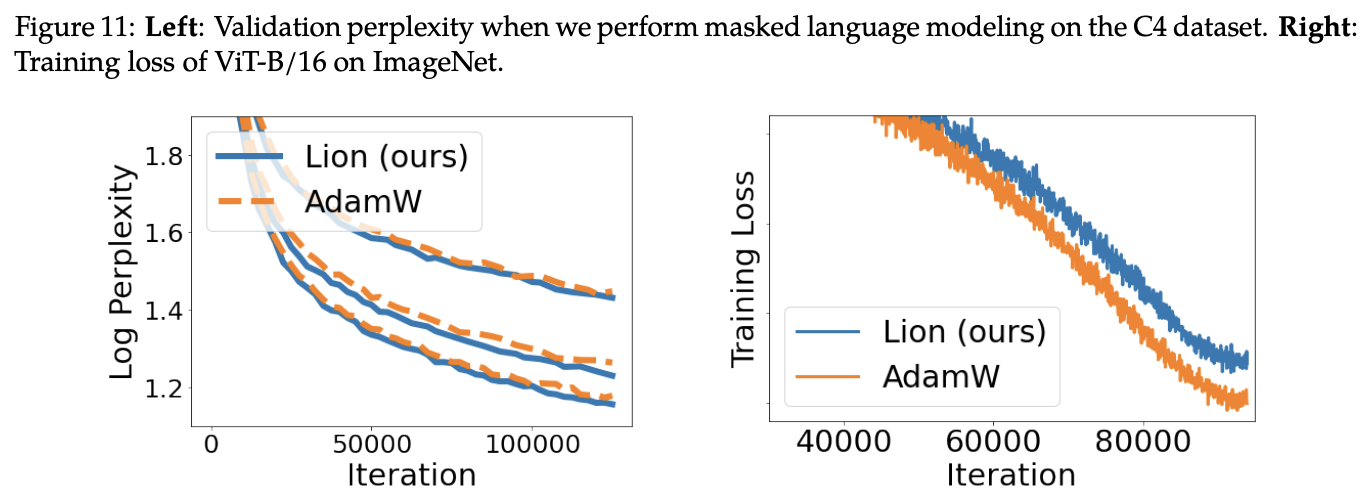

总体来看,Lion表现可圈可点,不管是原论文还是笔者自己的实验中,跟AdamW相比都有一战之力,再加上Lion更快以及更省显存的特点,或者可以预见未来的主流优化器将有它的一席之地。
自Adam提出以来,由于其快速收敛的特性成为了很多模型的默认优化器。甚至有学者提出,这个现象将反过来导致一个进化效应:所有的模型改进都在往Adam有利的方向发展,换句话说,由于我们选择了Adam作为优化器,那么就有可能将很多实际有效、但是在Adam优化器上无效的改动都抛弃了,剩下的都是对Adam有利的改进,详细的评价可以参考《NEURAL NETWORKS (MAYBE) EVOLVED TO MAKE ADAM THE BEST OPTIMIZER》。所以,在此大背景之下,能够发现比Adam更简单且更有效的优化器,是一件很了不起的事情,哪怕它是借助大量算力搜索出来的。
可能读者会有疑问:Lion凭啥可以取得更好的泛化性能呢?原论文的解释是 sign ext{sign} sign这个操作引入了额外的噪声(相比于准确的浮点值),它使得模型进入了Loss更平坦(但未必更小)的区域,从而泛化性能更好。为了验证这一点,作者比较了AdamW和Lion训练出来的模型权重的抗干扰能力,结果显示Lion的抗干扰能力更好。然而,理论上来说,这只能证明Lion确实进入到了更平坦的区域,但无法证明该结果是 sign ext{sign} sign操作造成的。不过,Adam发表这么多年了,关于它的机理也还没有彻底研究清楚,而Lion只是刚刚提出,就不必过于吹毛求疵了。
笔者的猜测是,Lion通过 sign ext{sign} sign操作平等地对待了每一个分量,使得模型充分地发挥了每一个分量的作用,从而有更好的泛化性能。如果是SGD,那么更新的大小正比于它的梯度,然而有些分量梯度小,可能仅仅是因为它没初始化好,而并非它不重要,所以Lion的 sign ext{sign} sign操作算是为每个参数都提供了“恢复活力”甚至“再创辉煌”的机会。事实上可以证明,Adam早期的更新量也接近于 sign ext{sign} sign,只是随着训练步数的增加才逐渐偏离。
Lion是不是足够完美呢?显然不是,比如原论文就指出它在小batch_size(小于64)的时候效果不如AdamW,这也不难理解,本来 ext{sign}已经带来了噪声,而小batch_size则进一步增加了噪声,噪声这个东西,必须适量才好,所以两者叠加之下,很可能有噪声过量导致效果恶化。另外,也正因为 sign ext{sign} sign加剧了优化过程的噪声,所以参数设置不当时容易出现损失变大等发散情况,这时候可以尝试引入Warmup,或者增加Warmup步数。还有,Lion依旧需要缓存动量参数,所以它的显存占用多于AdaFactor,能不能进一步优化这部分参数量呢?暂时还不得而知。
本文介绍了Google新提出的优化器Lion,它通过大量算力搜索并结合人工干预得出,相比主流的AdamW,有着速度更快且更省内存的特点,并且大量实验结果显示,它在多数任务上都有着不逊色于甚至优于AdamW的表现。
第一步,将如下代码添加到 中:
第二步,在中找到如下位置,添加 优化器的判断语句。
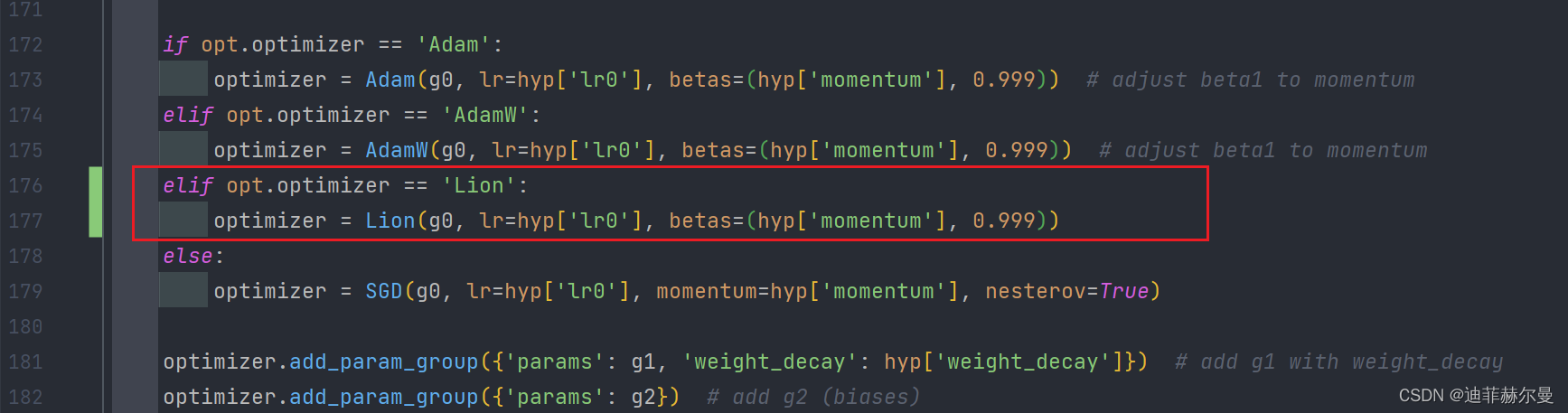
第三步,依然在 上方导入 优化器的名字;

第四步,更换优化器,训练模型。添加后,除原本的外,还可以选择 优化器。

训练时可以使用如下指令切换到 优化器;
最后附上论文部分实验结果: